Google’s tiny AI model ‘Gemma 2 2B’ challenges tech giants in surprising upset
Google’s Gemma 2 2B, a compact AI model with just 2.6 billion parameters, challenges industry giants by matching or surpassing larger models’ performance, revolutionizing AI accessibility and efficiency. …
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Google has just unveiled Gemma 2 2B, a compact yet powerful artificial intelligence model that rivals industry leaders despite its significantly smaller size. The new language model, containing just 2.6 billion parameters, demonstrates performance on par with or surpassing much larger counterparts, including OpenAI’s GPT-3.5 and Mistral AI’s Mixtral 8x7B.
Announced on Google’s Developer Blog, Gemma 2 2B represents a major advancement in creating more accessible and deployable AI systems. Its small footprint makes it particularly suitable for on-device applications, potentially having a major impact on mobile AI and edge computing.
The little AI that could: Punching above its weight class
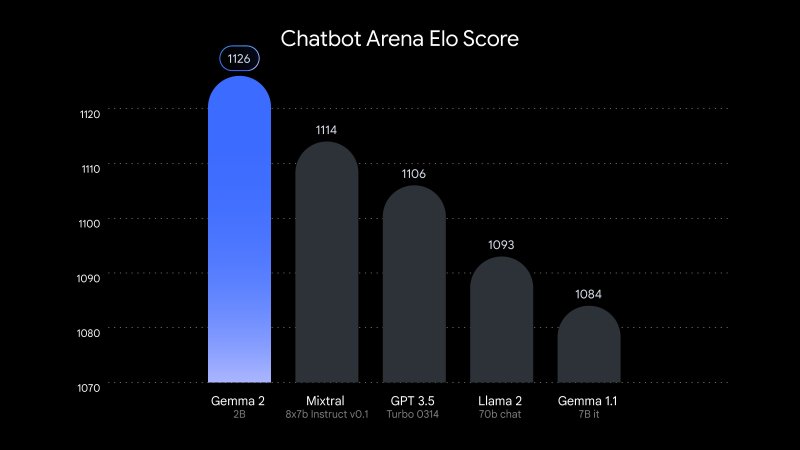
Independent testing by LMSYS, an AI research organization, saw Gemma 2 2B achieve a score of 1130 in their evaluation arena. This result places it slightly ahead of GPT-3.5-Turbo-0613 (1117) and Mixtral-8x7B (1114), models with ten times more parameters.
The model’s capabilities extend beyond mere size efficiency. Google reports Gemma 2 2B scores 56.1 on the MMLU (Massive Multitask Language Understanding) benchmark and 36.6 on MBPP (Mostly Basic Python Programming), marking significant improvements over its predecessor.
This achievement challenges the prevailing wisdom in AI development that larger models inherently perform better. Gemma 2 2B’s success suggests that sophisticated training techniques, efficient architectures, and high-quality datasets can compensate for raw parameter count. This breakthrough could have far-reaching implications for the field, potentially shifting focus from the race for ever-larger models to the refinement of smaller, more efficient ones.

Distilling giants: The art of AI compression
The development of Gemma 2 2B also highlights the growing importance of model compression and distillation techniques. By effectively distilling knowledge from larger models into smaller ones, researchers can create more accessible AI tools without sacrificing performance. This approach not only reduces computational requirements but also addresses concerns about the environmental impact of training and running large AI models.
Google trained Gemma 2 2B on a massive dataset of 2 trillion tokens using its advanced TPU v5e hardware. The multilingual model enhances its potential for global applications.
This release aligns with a growing industry trend towards more efficient AI models. As concerns about the environmental impact and accessibility of large language models increase, tech companies are focusing on creating smaller, more efficient systems that can run on consumer-grade hardware.
Open source revolution: Democratizing AI for all
By making Gemma 2 2B open source, Google reaffirms its commitment to transparency and collaborative development in AI. Researchers and developers can access the model through a Hugging Face via Gradio, with implementations available for various frameworks including PyTorch and TensorFlow.
While the long-term impact of this release remains to be seen, Gemma 2 2B clearly represents a significant step towards democratizing AI technology. As companies continue to push the boundaries of smaller models’ capabilities, we may be entering a new era of AI development—one where advanced capabilities are no longer the exclusive domain of resource-intensive supercomputers.