Meta unleashes its most powerful AI model, Llama 3.1, with 405B parameters
Llama 3.1 is the latest version of Meta’s large language models, with a new model weight, 405 billion parameters, the biggest model it’s trained. …
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
After months of teasing and an alleged leak yesterday, Meta today officially released the biggest version of its open source Llama large language model (LLM), a 405 billion-parameter version called Llama-3.1.
Parameters, as you’ll recall, are the settings that govern how an LLM behaves and are learned from its training data, with more typically denoting more powerful models that can ideally handle more complex instructions and hopefully be more accurate than smaller parameter models.
Llama 3.1 is an update to Llama 3 introduced back in April 2024, but which was only available until now in 8-billion and 70-billion versions.
Now, the 405 billion parameter version can “teach” smaller models and create synthetic data.
“This model, from a performance perspective, is going to deliver performance that is state of the art when it comes to open source models, and it’s gonna be incredibly competitive with a lot of the proprietary, industry-leading, closed source models,” said Ragavan Srinivasan, vice president of AI Program Management at Meta told VentureBeat in an interview.
Llama 3.1 will be multilingual at launch and will support English, Portuguese, Spanish, Italian, German, French, Hindi, and Thai prompts. The smaller Llama 3 models will also become multilingual starting today.
Llama 3.1’s context window has been expanded to 128,000 tokens — which means users can feed it as much text as goes into a nearly 400 page novel.
Benchmark testing
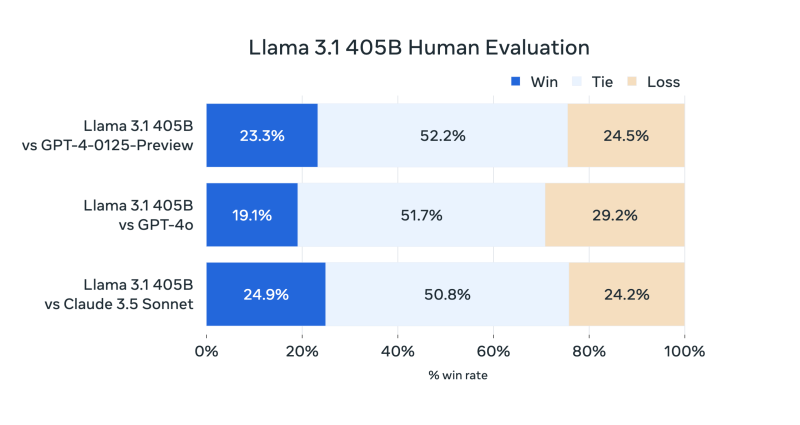
Meta said in a blog post that it tested Llama 3.1 on over 150 benchmark datasets and performed human-guided evaluations for real-world scenarios. It said the 405B model “is competitive with leading foundation models across a range of tasks including GPT-4, GPT-4o and Claude 3.5 Sonnet. The smaller-sized models also performed similarly.

The Llama family of models became a popular choice for many developers who could access the model on various platforms. Meta said Llama 3 could outperform or be on par with rival models on different benchmarks. It does well with multiple-choice questions and coding against Google’s Gemma and Gemini, Anthropic’s Claude 3 Sonnet, and Mistral’s 7B Instruct.
Teaching model
Meta also updated the license to all its models to allow for model distillation and synthetic data creation. Model distillation, or knowledge distillation, lets users transfer knowledge or training from a larger AI model to a smaller one.
Srinivasan called the 405B version a “teaching model,” capable of bringing knowledge down to the 8B and 70B models.
“The best way to think about the 405B model is as a teacher model. It has a lot of knowledge, a lot of capabilities and reasoning built into it,” Srinivasan said. “Once you use it, maybe it’s not directly deployed, but you can distill its knowledge for your specific use cases to create smaller, more efficient versions that can be fine-tuned for specific tasks.”
Through this model distillation, users can start building with the 405B version and either make a smaller model or train Llama 3.1 8B or 70B.
However, it isn’t just in the knowledge base that the 405B model could be useful in fine-tuning smaller models. The ability to create synthetic data will allow other models to learn from information without compromising copyright, personal or sensitive data, and fit for their specific purpose.
A different model structure
Meta said it had to optimize its training stack and used over 16,000 Nvidia H100 GPUs to train the 405B model. To make the larger model more scalable, Meta researchers decided to use a standard transformer-only model rather than a mixture-of-experts architecture that’s become popular in recent months.
The company also used an “iterative post-training procedure” for supervised fine-tuning and created “highest quality” synthetic data to improve its performance.
Like other Llama models before it, Llama 3.1 will be open-sourced. Users can access it through AWS, Nvidia, Groq, Dell, Databricks, Microsoft Azure, Google Cloud, and other model libraries.
AWS vice president for AI Matt Wood told VentureBeat that Llama 3.1 will be available on both AWS Bedrock and Sagemaker. AWS customers can fine-tune Llama 3.1 models through its services and add additional guardrails.
“Customers can use all of the publicly available goodness of Llama and do all sorts of interesting things with these models, take them apart, and put them back together again with all the tools available on AWS,” Wood said.
Llama 3.1 405B will also be available on WhatsApp and Meta AI.