SambaNova challenges OpenAI’s o1 model with Llama 3.1-powered demo on HuggingFace
SambaNova unveils a high-speed Llama 3.1-powered demo on HuggingFace, challenging OpenAI’s O1 model and transforming enterprise AI with open-source, scalable solutions. …
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
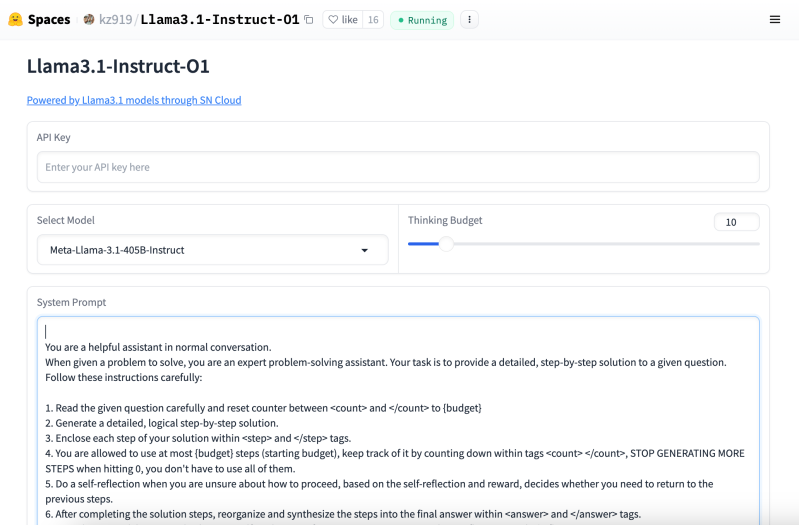
SambaNova Systems has just unveiled a new demo on Hugging Face, offering a high-speed, open-source alternative to OpenAI’s o1 model.
The demo, powered by Meta’s Llama 3.1 Instruct model, is a direct challenge to OpenAI’s recently released o1 model and represents a significant step forward in the race to dominate enterprise AI infrastructure.
The release signals SambaNova’s intent to carve out a larger share of the generative AI market by offering a highly efficient, scalable platform that caters to developers and enterprises alike.
With speed and precision at the forefront, SambaNova’s platform is set to shake up the AI landscape, which has been largely defined by hardware providers like Nvidia and software giants like OpenAI.

A direct competitor to OpenAI o1 emerges
SambaNova’s release of its demo on Hugging Face is a clear signal that the company is capable of competing head-to-head with OpenAI. While OpenAI’s o1 model, released last week, garnered significant attention for its advanced reasoning capabilities, SambaNova’s demo offers a compelling alternative by leveraging Meta’s Llama 3.1 model.
The demo allows developers to interact with the Llama 3.1 405B model, one of the largest open-source models available today, providing speeds of 405 tokens per second. In comparison, OpenAI’s o1 model has been praised for its problem-solving abilities and reasoning but has yet to demonstrate these kinds of performance metrics in terms of token generation speed.
This demonstration is important because it shows that freely available AI models can perform as well as those owned by private companies. While OpenAI’s latest model has drawn praise for its ability to reason through complex problems, SambaNova’s demo emphasizes sheer speed — how quickly the system can process information. This speed is critical for many practical uses of AI in business and everyday life.
By using Meta’s publicly available Llama 3.1 model and showing off its fast processing, SambaNova is painting a picture of a future where powerful AI tools are within reach of more people. This approach could make advanced AI technology more widely available, allowing a greater variety of developers and businesses to use and adapt these sophisticated systems for their own needs.

Enterprise AI needs speed and precision—SambaNova’s demo delivers both
The key to SambaNova’s competitive edge lies in its hardware. The company’s proprietary SN40L AI chips are designed specifically for high-speed token generation, which is critical for enterprise applications that require rapid responses, such as automated customer service, real-time decision-making, and AI-powered agents.
In initial benchmarks, the demo running on SambaNova’s infrastructure achieved 405 tokens per second for the Llama 3.1 405B model, making it the second-fastest provider of Llama models, just behind Cerebras. For the smaller 70B model, SambaNova reached 461 tokens per second, positioning itself as a leader in speed-dependent AI workflows.
This speed is crucial for businesses aiming to deploy AI at scale. Faster token generation means lower latency, reduced hardware costs, and more efficient use of resources. For enterprises, this translates into real-world benefits such as quicker customer service responses, faster document processing, and more seamless automation.
SambaNova’s demo maintains high precision while achieving impressive speeds. This balance is crucial for industries like healthcare and finance, where accuracy can be as important as speed. By using 16-bit floating-point precision, SambaNova shows it’s possible to have both quick and reliable AI processing. This approach could set a new standard for AI systems, especially in fields where even small errors could have significant consequences.
The future of AI could be open source and faster than ever
SambaNova’s reliance on Llama 3.1, an open-source model from Meta, marks a significant shift in the AI landscape. While companies like OpenAI have built closed ecosystems around their models, Meta’s Llama models offer transparency and flexibility, allowing developers to fine-tune models for specific use cases. This open-source approach is gaining traction among enterprises that want more control over their AI deployments.
By offering a high-speed, open-source alternative, SambaNova is giving developers and enterprises a new option that rivals both OpenAI and Nvidia.
The company’s reconfigurable dataflow architecture optimizes resource allocation across neural network layers, allowing for continuous performance improvements through software updates. This gives SambaNova a fluidity that could keep it competitive as AI models grow larger and more complex.
For enterprises, the ability to switch between models, automate workflows, and fine-tune AI outputs with minimal latency is a game-changer. This interoperability, combined with SambaNova’s high-speed performance, positions the company as a leading alternative in the burgeoning AI infrastructure market.
As AI continues to evolve, the demand for faster, more efficient platforms will only increase. SambaNova’s latest demo is a clear indication that the company is ready to meet that demand, offering a compelling alternative to the industry’s biggest players. Whether it’s through faster token generation, open-source flexibility, or high-precision outputs, SambaNova is setting a new standard in enterprise AI.
With this release, the battle for AI infrastructure dominance is far from over, but SambaNova has made it clear that it is here to stay—and compete.